- Details
- Category: documentation
Last update: 25/10/2022
The European Databases of Seismogenic Faults (EDSF) installation operates under the auspices of the EPOS TCS-Seismology work program, particularly those of the EFEHR Consortium, and considers the principles expressed by the EPOS Data Policy. EDSF offers services that distribute data about seismogenic faulting proposed by the scientific community or solicited to the scientific community or stemming from project partnerships that involved the use or development of the EDSF installation itself. The following flowchart summarizes how the EDSF Core Team (CT) carries out quality control of the distributed data.
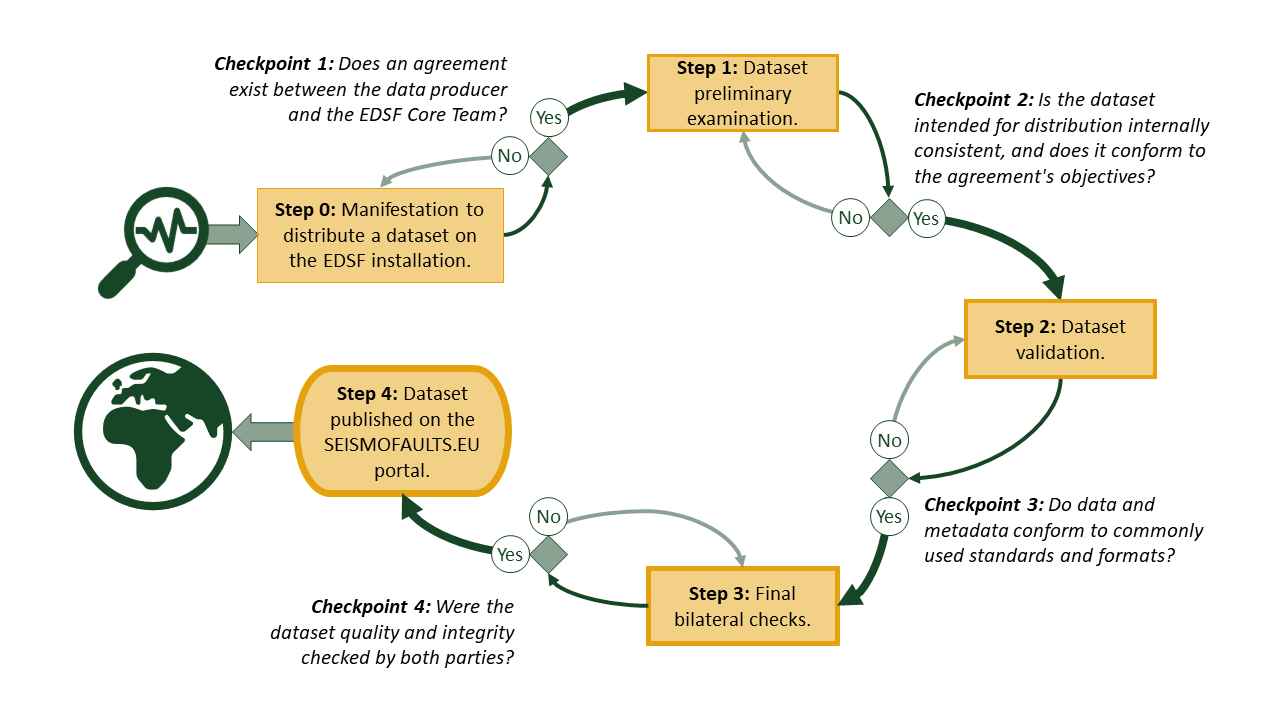
Description of the actions performed at each step of the Quality Control process.
Step 0: Manifestation to distribute a dataset on the EDSF installation.
The data intended for distribution must address the objectives of the EDSF installation. The data producer must confirm full ownership rights to the data product to establish a formal agreement with the EDSF CT to redistribute the data and establish a roadmap toward adopting the FAIR principles. Bypassing the formal agreement is possible when the data producer operates in the framework of a project involving both parties (e.g., a consortium agreement of a European project). The data ownership, authorship, or any other right, obligation, or restriction remains with the data producer. Importantly, none of these rights or obligations can be transferred to the EDSF CT by any means, assumed or implied, neither during the Quality Control process nor after its completion, regardless of its outcomes.
Checkpoint 1: Does an agreement exist between the data producer and the EDSF CT?
Step 1: Dataset preliminary examination.
The data producer shares the dataset intended for distribution with the EDSF CT. The data should be made available on a platform/system and using formats that allow the EDSF CT to examine it without further interventions by the data producer. Proper documentation detailing the data structure should accompany the data submission. If the data description does not conform to the submitted data, the EDSF CT invites the data producer to fix the issues before proceeding to the next step. At this stage, the data sharing between the involved parties remains confidential.
Checkpoint 2: Is the dataset intended for distribution internally consistent, and does it conform to the agreement's objectives?
Step 2: Dataset validation.
The EDSF CT checks and validates the data and metadata, ensuring that they conform to commonly used standards and formats. They also identify if any inconsistency in the data structure exists. The documentation should comprehensively describe the dataset properties and all its components. It should also address the dataset's potential limitations.
Checkpoint 3: Do data and metadata conform to commonly used standards and formats?
Step 3: Final bilateral checks.
The EDSF CT prepares the web services in the formats prescribed by the installation. The EDSF installation uses the Open Geospatial Consortium (OGC) standards for data containing geospatial information. The EDSF CT and the data producers interact to verify that the web service distribution conforms to the submitted data. Once the web services are approved, they become available on the SEISMOFAULTS.EU portal with restricted access for the final quality and integrity check and an additional check done by the data producer.
Checkpoint 4: Were the dataset quality and integrity checked by both parties?
Step 4: Dataset published on the SEISMOFAULTS.EU portal.
At this step, both parties have performed all the necessary checks. The data producer and the EDSF CT agree to publish the dataset web services. The EDSF CT affixes the Creative Commons 4.0 CC-BY license to the distributed dataset without further licensing information and removes all the access restrictions to the dataset. A recognized organization (e.g., DataCite) must have minted a Digital Object Identifier (DOI) that identifies the dataset. If a landing page linked to the DOI does not exist, the EDSF installation can provide space to host it. Any web page or link to the data, metadata, technical documentation and any other relevant information connected to the dataset initially covered by confidentiality should also be made publicly available. The data distribution becomes public.
- Details
- Category: documentation
The main purpose of the European Databases of Seismogenic Faults (EDSF) installation is to publish datasets through the open standards developed by the Open Geospatial Consortium (OGC) and to host a large part of the data behind those datasets. Read the extended report that illustrates the main characteristics of the IT infrastructure, called SEISMOFAULTS.EU, which serves these purposes. The front end of the infrastructure is the EDSF portal. However, a few other portals and websites are hosted on "SEISMOFAULTS.EU" to provide a user interface with other activities related to sibling projects.
If you are in a hurry, scroll down this web page for a summary.
Implementation
Hardware
SEISMOFAULTS.EU is hosted in three dedicated physical servers belonging to the INGV IT infrastructure:
- N. 1 Hewlett Packard Enterprise (HPE) ProLiant BL460c (Gen9) equipped with two Intel® Xeon® CPU E5-2640 v4 @ 2.40GHz processors with 10/10 cores, 20 threads; 128 GB of RAM for every CPU with a frequency of 2133 MHz; two HDD HPE of 300GB in Raid 1.
This server is entirely dedicated to development and testing.
- N. 2 HP ProLiant DL560 (Gen10) equipped with 4 Intel® Xeon® Gold 5118 CPU @ 2.30GHz 12/12 cores, 24 threads processors with 64 GB of RAM for every CPU with a frequency of 2400 MHz; four HDD da 300 GB in Raid 5 and 4 SSD da 1920 GB in RAID 5.
In addition, 50TB of storage hosted by the Storage Area Network (SAN) of Centro Servizi Informativi (CSI) of INGV premises in Rome is dedicated to our installation.
The ProLiant BL460c and one of the DL560 are hosted in CSI's data centre; the other DL560 is hosted in the INGV premises in Bologna.
Software
Following the recommendations of Agenzia per l’Italia Digitale (AGID) contained in the “Linee guida acquisizione e riuso software PA” SEISMOFAULTS.EU implements almost only open-source software.
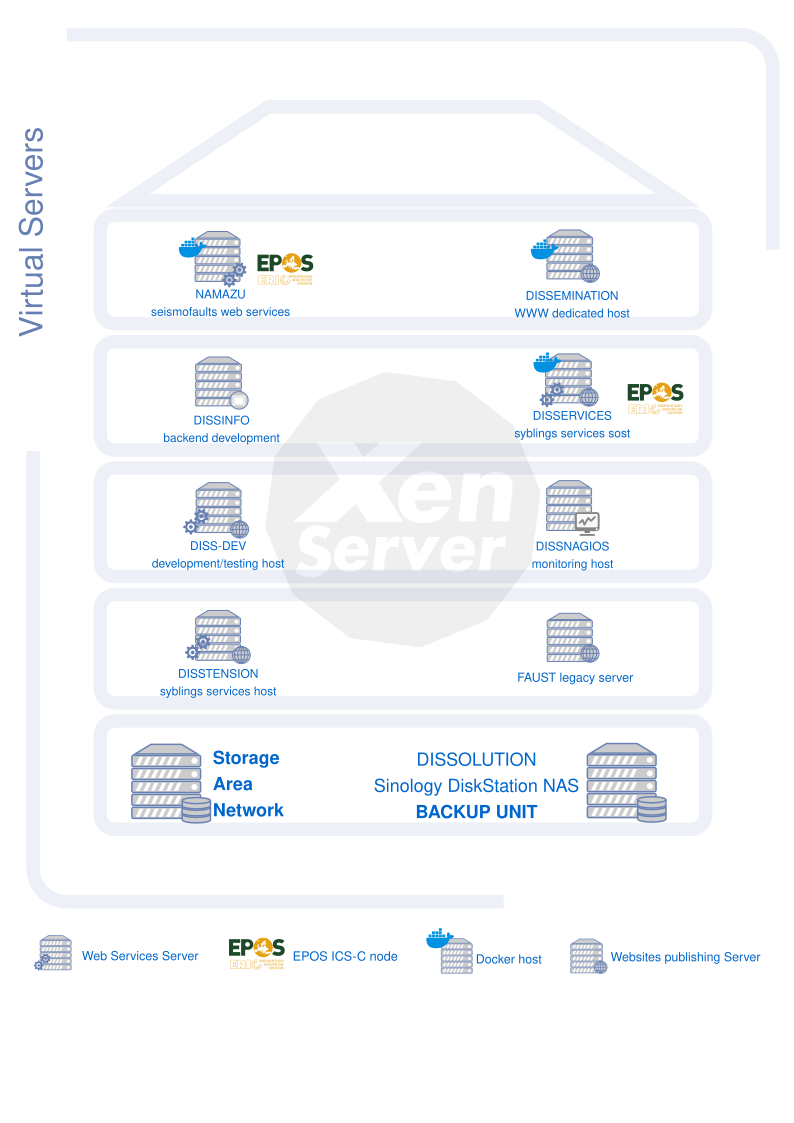
We installed XenServer Hypervisor on each physical server for creating and managing virtual machines (VMs). Debian Linux OS is installed on all the VMs except for one, on which the MS Windows Server 2016 is installed for running applications devoted to activities not directly related to the data distribution (figure below).
The web portals and websites are managed through Joomla! or WordPress Content Management System (CMS).
The OGC web services are published through the GeoServer software, while the data management in the backend is done with PostGIS.
All services and websites are containerized through Docker Containers technology.
Docker containers are a virtualization technology that creates isolated applications or services in an autonomous environment. This environment includes all the applications/services needed to be executed: dependencies, libraries, and configuration files.
Even if there are some similarities, containers are different from VMs for several reasons:
- They share the same kernel and operating system, making them more efficient and less resource-intensive than VMs;
- They can be created, deleted, and run faster, making them ideal for microservices implementation and applications that need few resources and great scalability;
- They are portable: once created and customized, they can be deployed and run on almost every platform that can run the Docker runtime engine;
- They can be easily deployed in the cloud or mixed environments;
- They offer higher security. A (carefully configured) container is an environment isolated from the host OS and other containers. A malfunction or compromise does not affect other containers or the host OS.
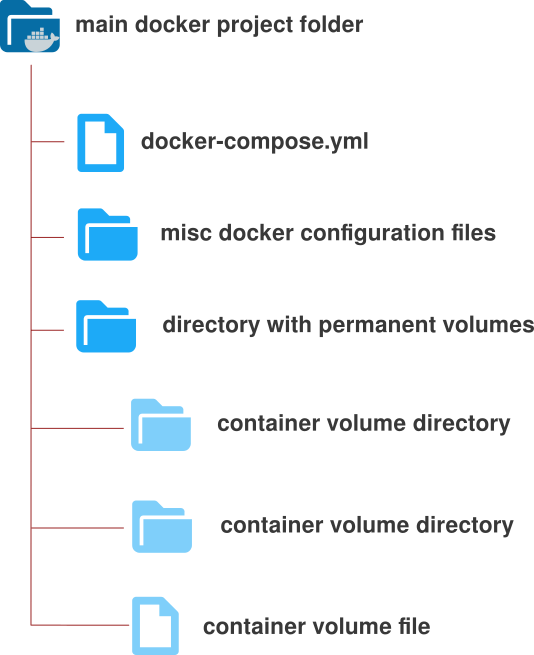
The typical file system organization of a “dockerized” service inside SEISMOFAULTS.EU can be summarized as follows:
- A main directory “to hold them all” with a name reminiscent of the name of the service. It might also be a GIT repository (see below);
- A docker-compose.yml file containing details about the services, networks, and volumes for setting up the application’s environment. It is used to create, deploy, and manage service-related containers;
- A directory containing volumes is a way to store and manage data generated by and used by Docker containers. Volumes exist outside of the Docker container and can persist data even if the container is destroyed or moved. They typically store and share data between multiple containers or with the host OS (see figure below).
We recommend the official documentation to provide a full understanding of how Docker works.
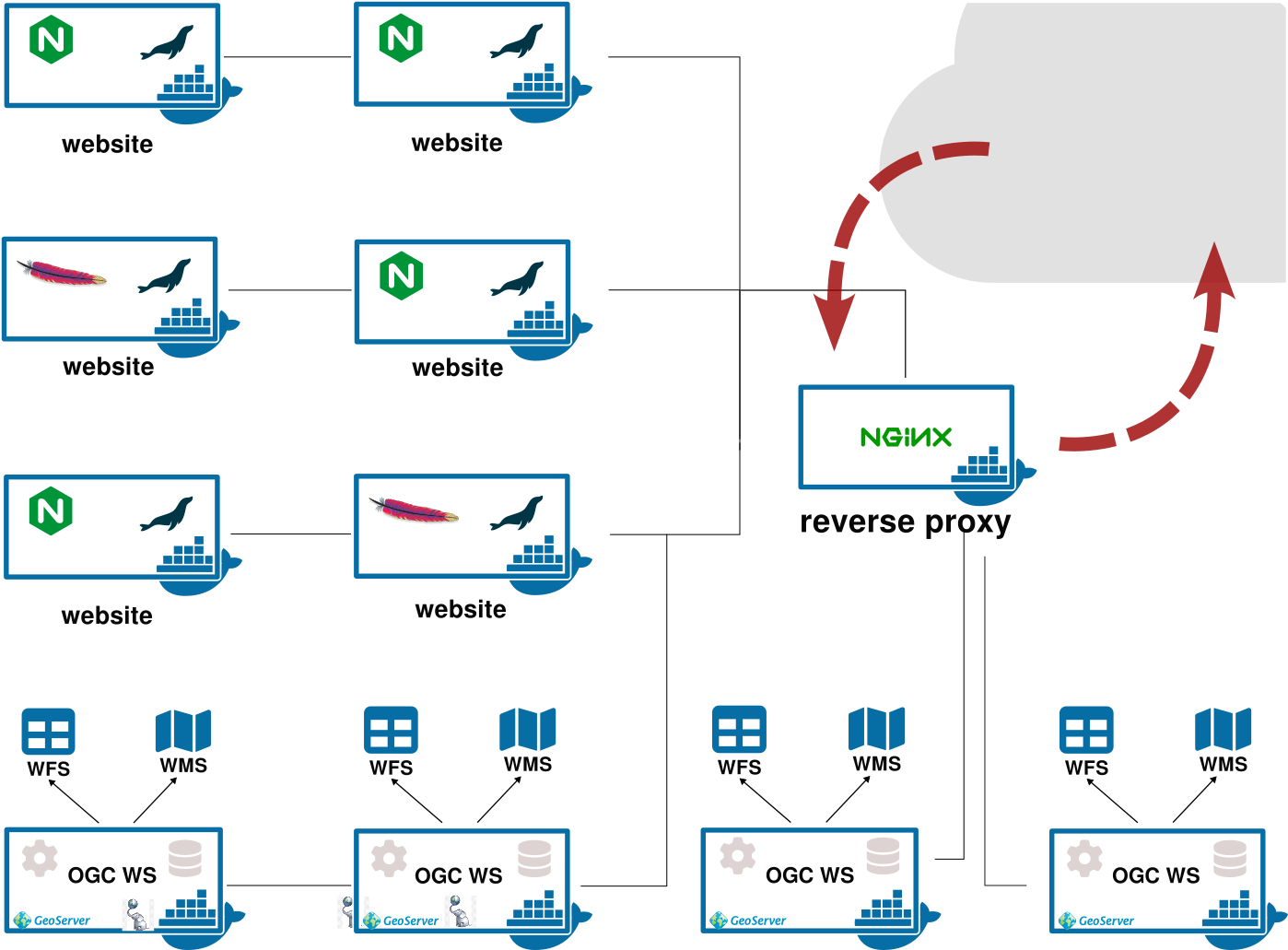
Several websites and web services run on the same VM. Every website or web service includes its web server (Nginx or Apache), web application server (i.e., Apache Tomcat), and related RDBMSs.
A (dockerized) reverse proxy manages network traffic routing arriving and departing connections from and to the suitable container hosting the service requested by the user.
Git
Service-related directories are managed through Git.
Git is a version control system designed to handle software development projects. It is a distributed version control system, meaning each user can have a local copy of the repository, making it easier to collaborate with other users.
Every Docker project directory is also a Git repository. In this way, the Git system tracks every configuration change and synchronizes the sysadmin workstation and the server running the services straightforwardly, often automatically.
Security
All VMs are implemented with a strong rationalization of active services to limit unnecessary port exposure to the internet as far as possible.
Some VMs are available only from the institutional intranet and accessible only through a Virtual Private Network (VPN). VMs that publish web services are protected by a few simple firewall rules.
Software updates
The OS and application software updates are performed from some scripts that are periodically and automatically launched using standard Unix tools. The system administrator makes manual revisions of updates on a weekly schedule.
The system administrator manually curates docker image updates, generally performed when image distributors release security patches.
Backup
System backups are performed at several independent levels:
- VM snapshots are periodically made through the Hypervisor user interface;
- Several scripts are executed nightly to perform a backup of the main directories of the VM OSs.
Backups are moved in disk partitions normally unused by OS and periodically copied inside a Network Attached Storage (NAS).
Monitoring
Monitoring is the process of collecting, analyzing, and displaying performance data used to measure the performance of an IT system. The goal is to ensure the system’s availability, performance, and security. We monitor the SEISMOFAULTS.EU installation to measure the performance of applications, databases, networks, and servers. Performance metrics such as latency, throughput, availability, and utilization provide a clear picture of the system's health and can identify potential areas of improvement to take corrective action when needed. Monitoring can also provide insight into the security of the system. It can detect unauthorized access attempts, malware, and other malicious activity.
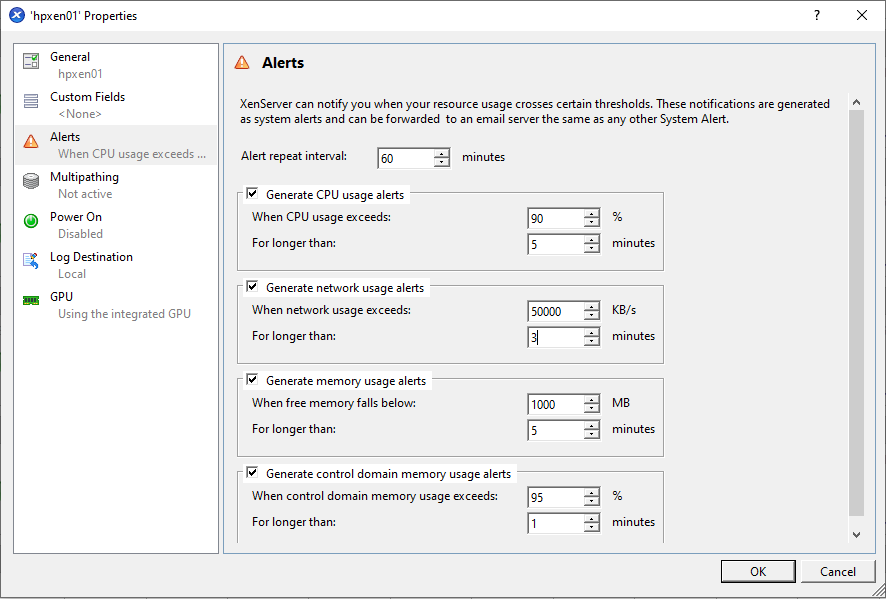
The SEISMOFAULTS.EU infrastructure monitoring is performed at multiple levels. The first level is performed by the VM hypervisor, which notifies the system administrator if a VM has anomalous behaviours, such as excessive disk or CPU activity for an extended time, a saturation of memory space, or abnormal network traffic (figure below).
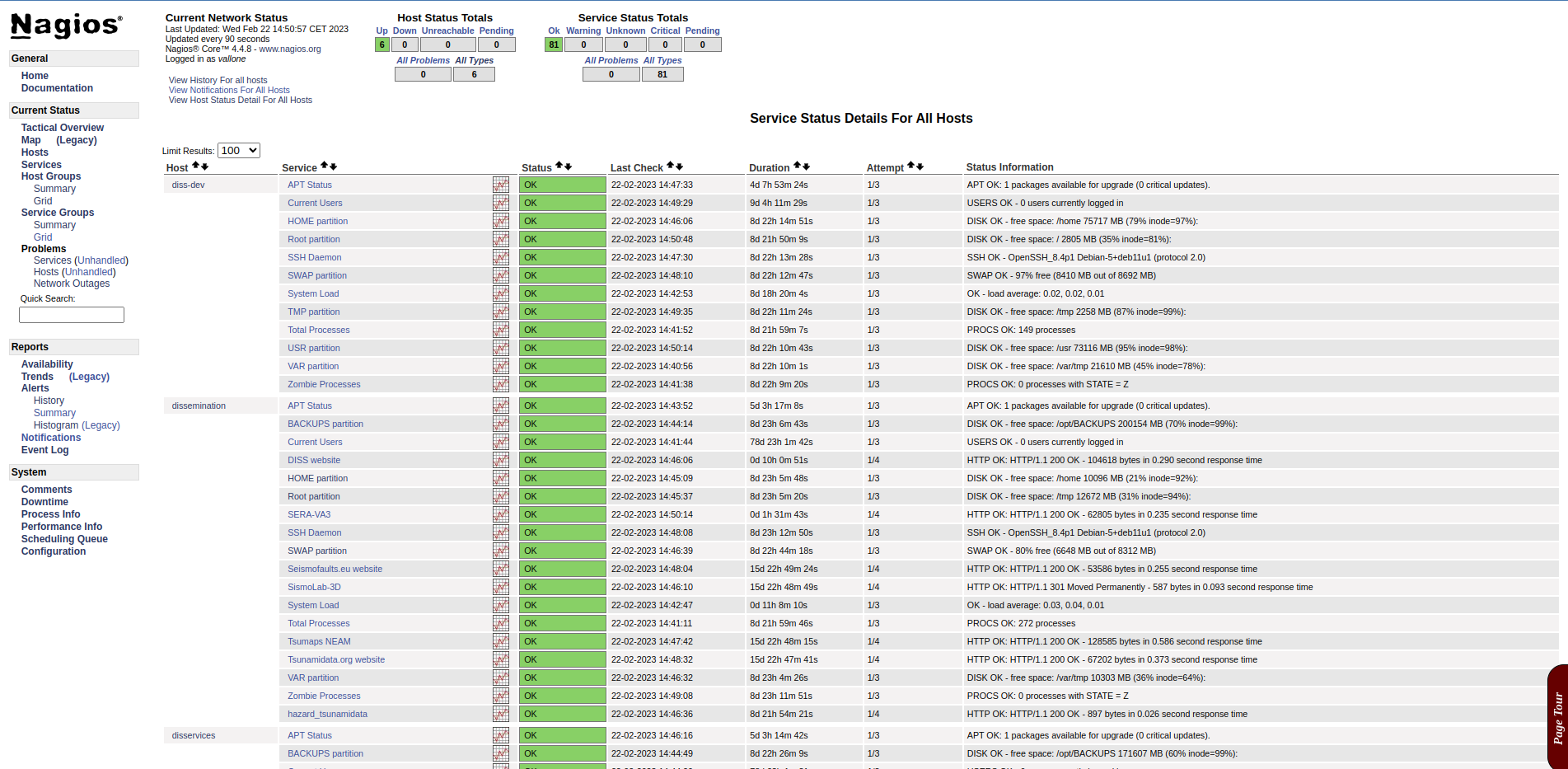
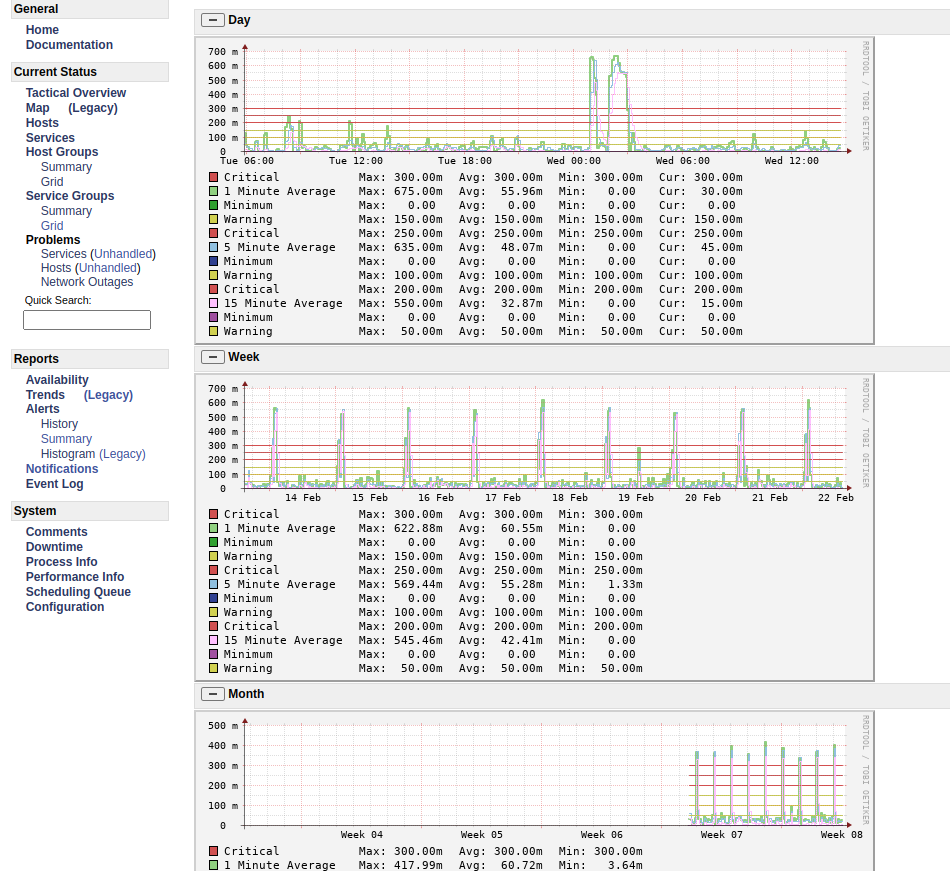
Nagios, software specifically designed for this task and configured on a dedicated VM, performs a second level.
Nagios monitors both VMs at the OS level (processes, CPU load, RAM usage, disk partition usage, logged users, etc.) and the process level (services and websites). It is configured to notify the system administrator via email or Telegram in case of malfunction (figures below).
Security administration policy for the systems includes, in addition, software updates, backup, and monitoring.
Access Statistics
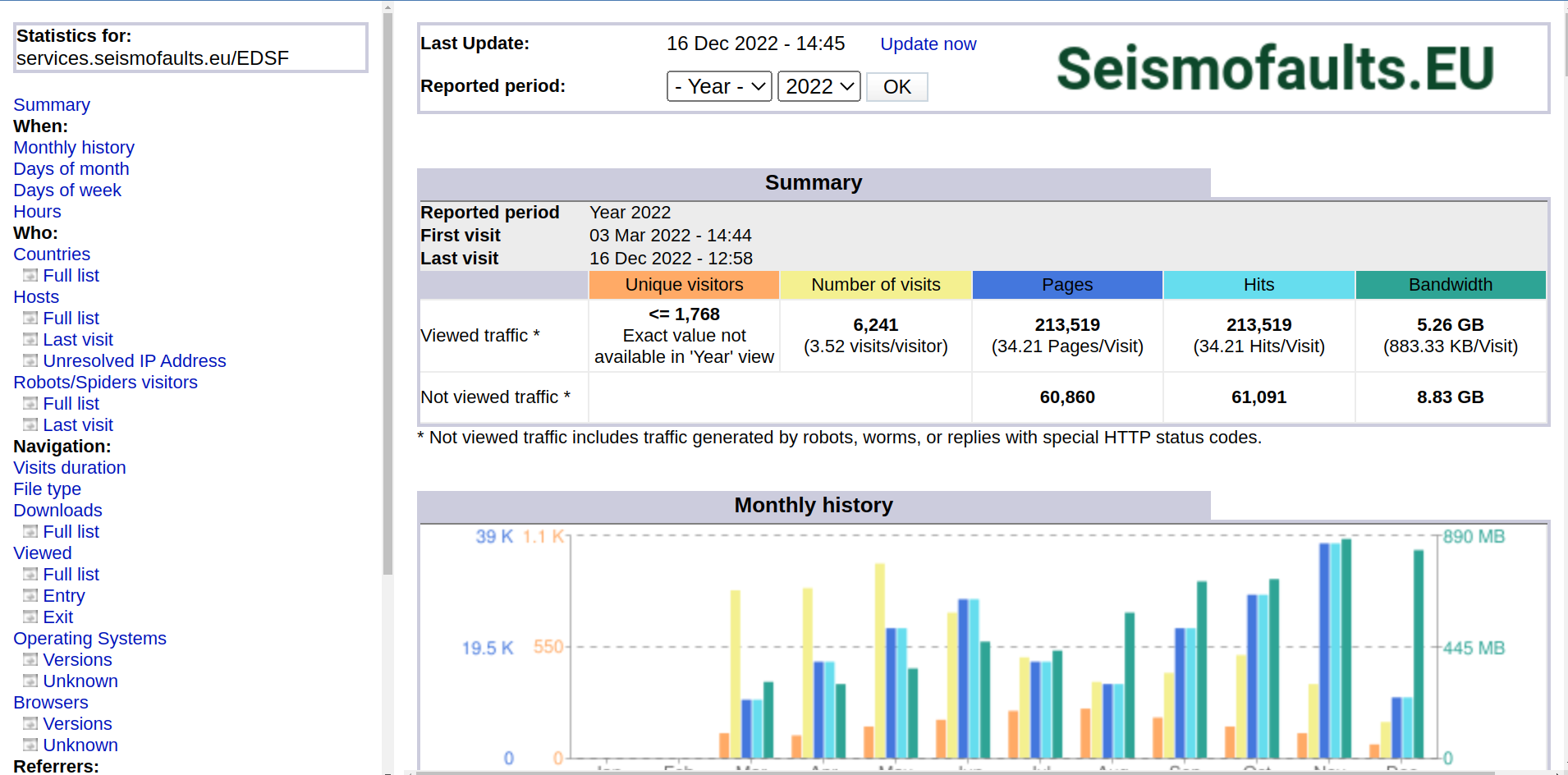
"SEISMOFAULTS.EU" uses two approaches to monitor access and report usage statistics for websites and web services because of the different technologies underlying their operation.
Website access statistics are created through the Google Analytics platform, whereas web services access statistics are created using AWStats software. Google Analytics works through a javascript that “intercepts” the connections to every website web page and stores data in the Google Cloud for various analyses (figure below). AWStats, instead, is a Perl script installed on the same VMs that publish the services. It analyzes the logs generated by the web application manager that runs GeoServer and produces a webpage with a set of stats as an output (figure below).
Acknowledgements
We thank all the INGV staff of Centro Servizi Informativi, particularly Giovanni Scarpato, Stefano Cacciaguerra, Pietro Ficeli, Manuela Sbarra, Gianpaolo Sensale, Diego Sorrentino, Stefano Vazzoler, Francesco Zanolin for their continuous IT support; the EPOS Integrated Core Services staff of the EPOS office in Rome: Daniele Bailo, Kety Giuliacci, Rossana Paciello, and Valerio Vinciarelli for their effort in EPOS/SEISMOFAULTS.EU cooperation; and our colleagues Valentino Lauciani for suggestions on the Docker configuration, Matteo Quintiliani for managing the INGV GitLab installation, and Giorgio Maria De Santis, Mario Locati, and Gabriele Tarabusi for the fruitful exchange of views.
The development of the SEISMOFAULTS.EU infrastructure benefitted from the funding of H2020 projects EPOS IP (grant agreement No. 676564) and SERA (grant agreement No. 730900), the JRU EPOS ITALIA Piano di Attività 2021 2024 supported by the Italian Ministry of University and Research (MUR), and the DPC INGV Agreement 2012 2021 (Annex A) and 2022 2024 (Annex A).
- Details
- Category: documentation
The European Databases of Seismogenic Faults (EDSF) installation offers services that distribute data about seismogenic faulting proposed by the scientific community or solicited to the scientific community or stemming from project partnerships that involved the use or development of the EDSF installation itself. The first item in the list below is the DMP of the entire EDSF installation. Each dataset distributed through EDSF may have its own DPM. When such DMPs are public, we link them to the list.
- Data Management Plan of the EDSF Installation (Horizon Europe template)
- Data Management Plan of the EFSM20 dataset (DCC template)
- Data Management Plan of the DISS datasets (DCC template)
- Data Management Plan of the EDSF13 dataset (DCC template)
- Data Management Plan of the G-DIP dataset (DCC template)
- Data Management Plan of the MEET WP11 A11.9a datasets (DCC template)
- Details
- Category: documentation
- Details
- Category: documentation